Transformer is all you need
Published:
参考链接:
https://cloud.tencent.com/developer/article/1776357 (很长但是看完很有收获)
RNN:
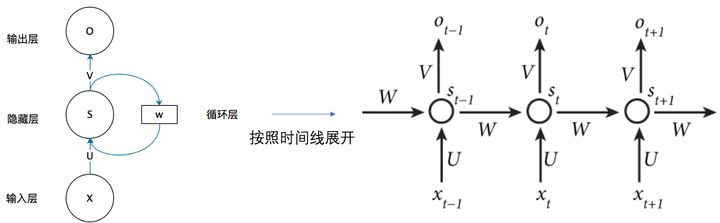
RNN在MVS 中的应用:Recurrent MVS系列:
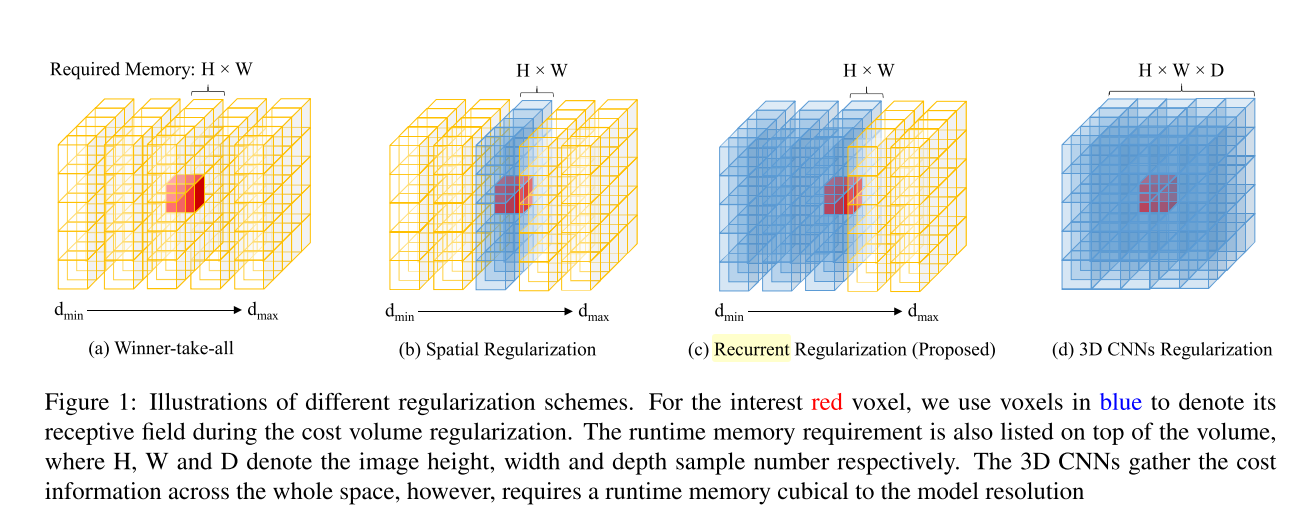
RNN相对于CNN的缺点:计算时不能并行,在有时序or顺序的情况下,不能看到后面的信息,当前最优解是通过当前及之前的信息得出的,好处是相对于3D的CNN,可以维护更少的数据,占用内存少。(变长序列padding?)
Transformer:
Attention机制:
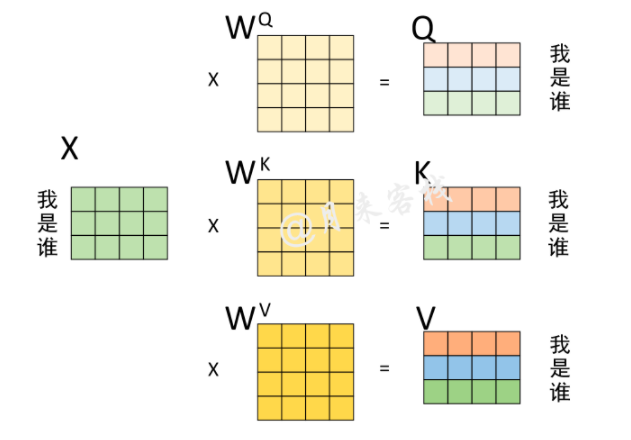
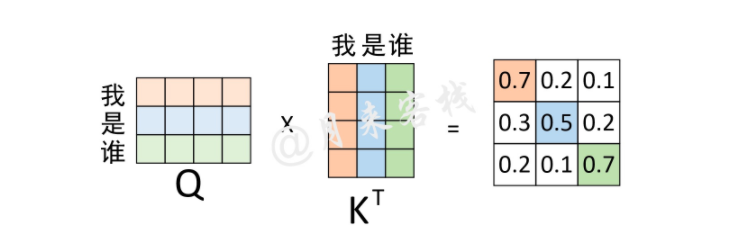
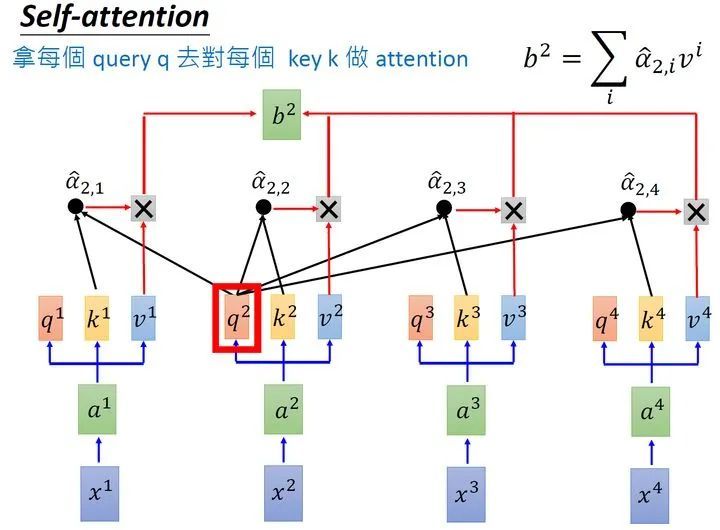
self-attention:从形式上看是一个全局的信息,矩阵求内积表示,每个位置两两之间的注意力值,比如\(QK^T\)矩阵相乘之后,(1,1)的位置表示\(Q_{11}\)对\(K_{11}\)的权值/注意力,对于一个输入\(X\),忽略掉batch,输入维度为:[seq_length, feature_length],这样的相乘方法表示的应该是一个序列中每一个特征值,两两之间的互相影响关系,既包括序列之间不同位置之间的权值,也包含不同特征值之间的权值
for example (from post ):
同理,对于权重矩阵的第3行来说,其表示的含义就是,在对序列中”谁“进行编码时,应该将0.2的注意力放在”我“上,将0.1的注意力放在”是“上,将0.7的注意力放在”谁“上。从这一过程可以看出,通过这个权重矩阵模型就能轻松的知道在编码对应位置上的向量时,应该以何种方式将注意力集中到不同的位置上。
从上面的计算结果还可以看到一点就是,模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置(虽然这符合常识)而可能忽略了其它位置。因此,作者采取的一种解决方案就是采用多头注意力机制(MultiHeadAttention)
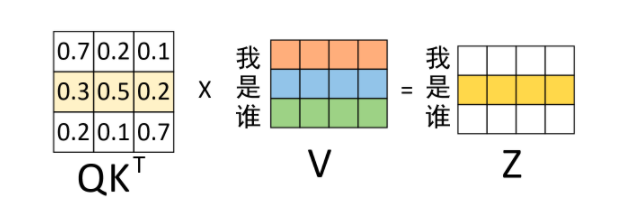
矩阵乘法还可以写成列向量or行向量的线性组合:

计算公式:
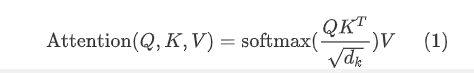
除以\(d_k\)是由于当维度增加时,\(QK^T\)的值会变得比较大,softmax之后梯度变小,因此需要rescale
对于每个输入,有(输入里已经包含了seq_length,为什么这里还有好几个X输入?)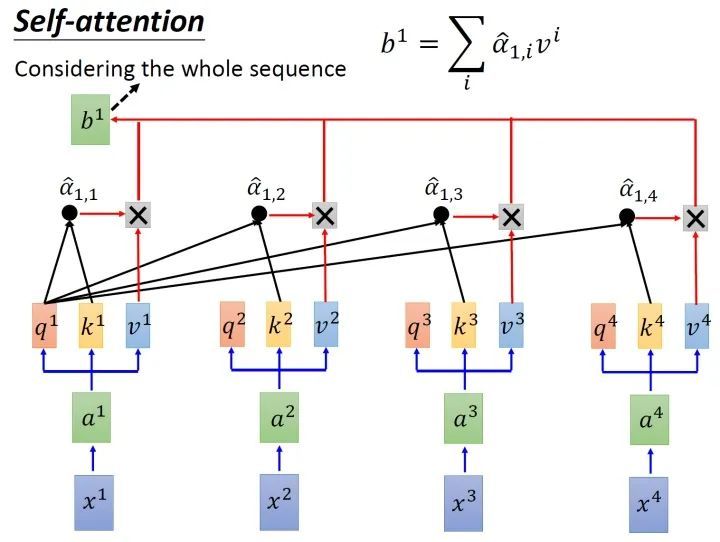
Multi-head 机制:
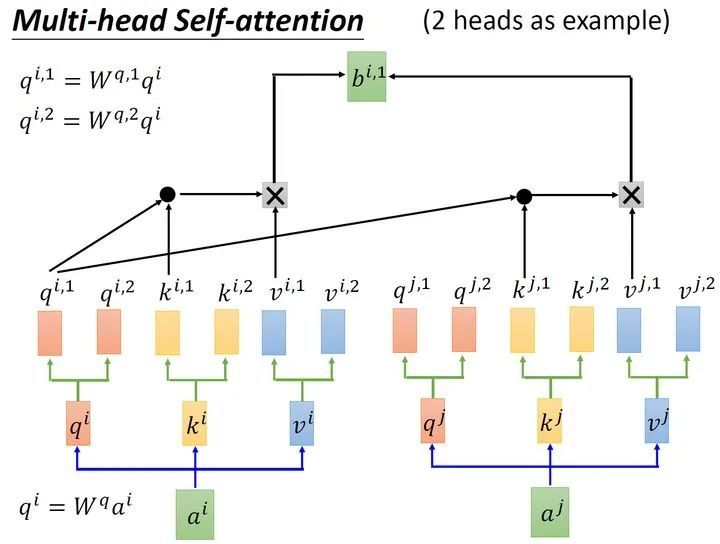
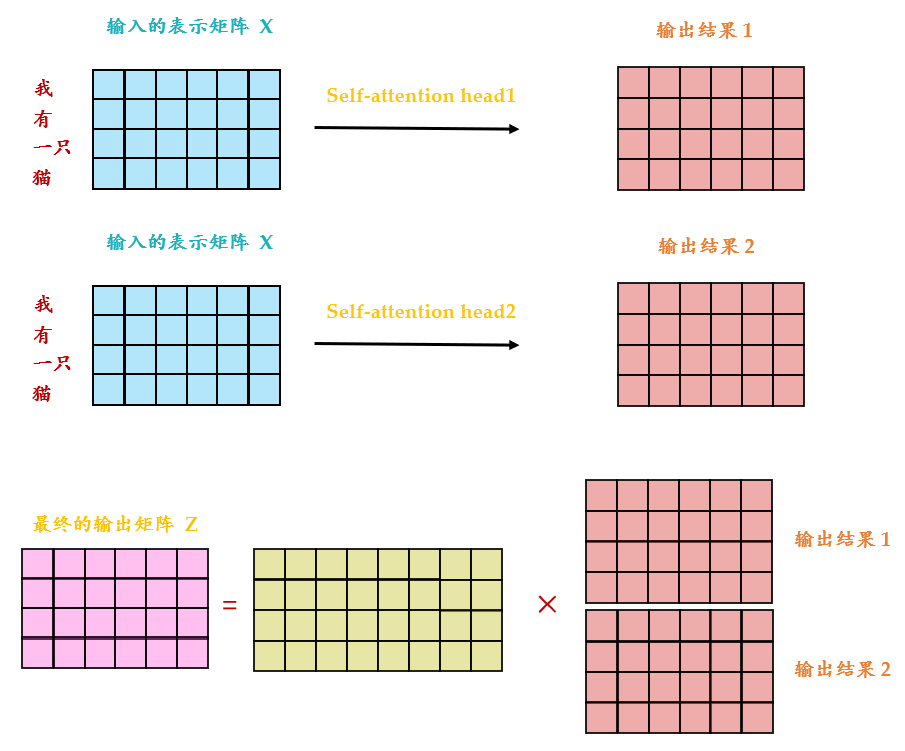
明白了attention机制之后,multi-head这一部分就比较简单了,也是一个简单的矩阵乘法
Position Embedding / Encoding
reference: Transformer中的position encoding
为什么需要P.E:这样点积矩阵相乘的形式,导致了在计算权重的时候没有考虑到位置信息对于权重的影响。对于编码的需求:
- 同一单词在不同位置的需求,体现先后的次序,编码不应随着文本长度变化而变化
- 有值域,不能无限延申 (单调递增/递减 不满足——>周期函数?)
周期函数的好处是可以复用值域,如下图所示的周期函数:
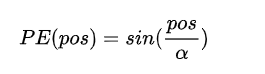
但是,\(\alpha\)表示波长和序列长度,当序列长度长的时候,相邻位置函数值区别很小,这样的编码方式太单调,由于字嵌入不止一个维度\(d_{k}\),因此用\([-1,1]^{d_{k}}\)的值域范围来表示
对于某位置t和对应的偏移量k,\(PE_t^T PE_{t+k}\)仅取决于\(k\),也就是说两个位置编码的点积可以反应两个位置之间的距离:
\(PE_t^T PE_{t+k} = \sum_{j=0}^{d/2-1} cos(c_jk)\)
其次,位置编码是没有方向性的:
\(PE_t^T PE_{t+k} = PE_{t-k}^T PE_{t}\)
为什么要使用相加的方式,参考知乎回答:
Transformer使用position encoding会影响输入embedding的原特征吗? - LooperXX的回答 - 知乎 https://www.zhihu.com/question/350116316/answer/863151712
MLP 、CNN VS. Transformer:
reference:CNN,Transformer,MLP三大架构之战
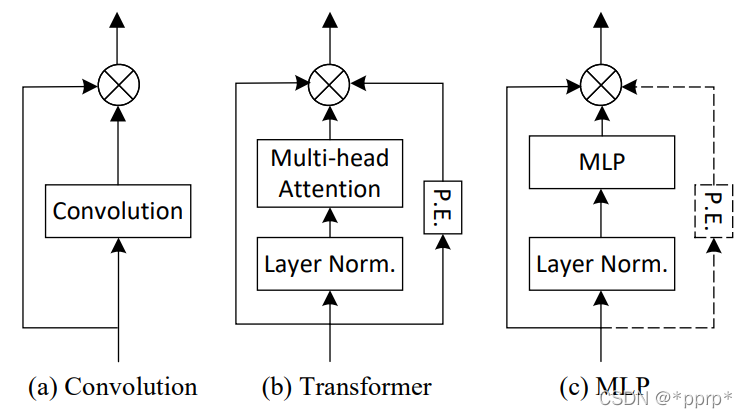
- MLP和transformer都可以看到全局的信息(CNN是局部,RNN是当前+之前所有信息)
- MLP容易过拟合:在DeepSDF和pifu,nerf等文章中,作者都是使用MLP作为网络结构,对于每一个场景or每一个特殊的物体,train一个包含特异性信息的latent code,在测试的时候query,从而达到任意精度的查询,或者做一个infer,但是我们从pifu的效果中也可以看到,这样的MLP会损失很多的高频信息。降低MLP过拟合的方法:
- multi-stage网络机制
- 权重共享机制,还有今天面试学到的weight-decay(权重衰减)
- CNN有更强的泛化性,while Transformer有更大的网络容量(互补),因此可以融合CNN和Transformer的架构来获得更好的性能